
Subtitle: SHAME ON YOU MICROSOFT!
This is not a new behavior. It’s not a new risk. It’s the same old risk that’s been in Windows Failover Clustering for quite some time. But it’s worse for SQL Server environments that use a Windows failover cluster for an Availability Group – since you are not sharing storage for an AG (unless for some odd reason you wanted to have a quorum drive.)
I’m pretty sure I learned this one the hard way myself when the task of adding a new node to a windows cluster fell on me. Everything I had read suggested you should run a validation. Good to make sure all is ready, right? I mean. It’s called validation that sounds like a safe and mostly good thing. Anyway, I ran it and all of the drives went away. In this case wayyyy back when it wasn’t a big deal, it was pre-production and the drives weren’t vital – but my heart stopped beating, my stomach knotted up and my vision narrowed. Time slowed. Yup. An adrenaline dump.
Short story: When you choose the default options in Validation – any storage that could be possibly shared storage is taken offline and brought into the cluster’s available storage role. And I mean any storage. So if you run validation on a live Windows Failover Cluster that is hosting, say, an Availability Group, with disks backed by iSCSI – those drives will be sucked away from the nodes in the cluster and brought into the available storage. Unceremoniously your drives will all disappear from you in file explorer, you SQL Server databases will come crashing down and folks will start calling you asking “Where did the drives go?! Where is my database?! WHAT THE HECK DID YOU DO!!!!!!!” And then when you sort it out and bring stuff back online – you could have corrupt databases, because you didn’t really tell SQL Server, “pssst…. Hey.. I’m taking your drives offline and in no specific order. Good luck!”
I get reminded of the flaw of Microsoft not having a big flashing ARE YOU SURE?!?!?!?!?!? dialog every so often when I see someone in a forum have an oops. Most recently, we were helping a brand new client who was suffering some pretty serious performance issues (don’t ask me about what I think about hyperconverged architecture for high performance SQL Servers today.. Suffice it to say things were better with a move away from it back to the “old” In fact in general, don’t ask me that question unless you can handle the truth.. We’ve seen too many scars… Anyway… This is about Microsoft and the one place they still haven’t put a confirmation warning not hyperconverged infrastructure….). We started getting things into a good spot and had some plans in place. And the infrastructure folks were adding a new node to the windows cluster to add to the AG to make a move. All of the sudden everything died. It took me about 90 seconds of troubleshooting, “Shoot! Someone is probably doing a validation of the cluster someplace!!!” I announced on the call. “Yeah. That was happening.” We got the drives back (Removed them all from available storage) and got SQL back, and only had “minimal” corruption (TempDB one of othe nodes, a big DB on the other – thankfully only a secondary in the AG. Primary was clean. Though a weekend checkdb will confirm that…)
So here’s what happens:
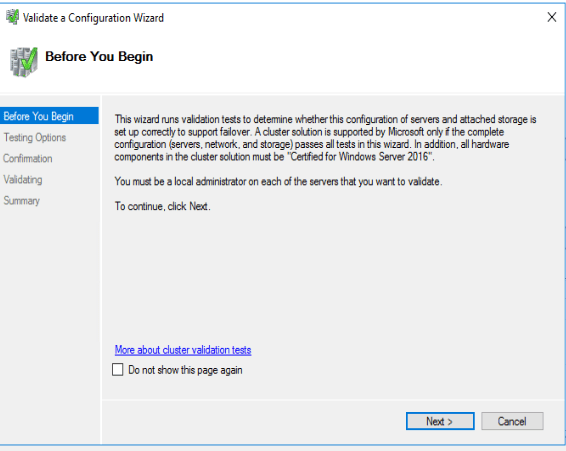
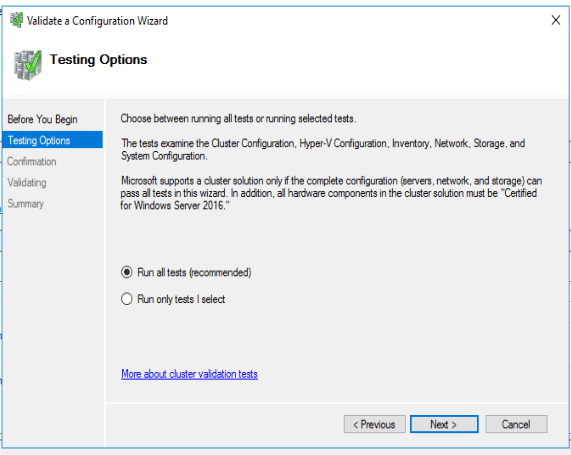

So. For the love of all that’s good and proper – just instead tick “Run only tests I select” if you don’t want to blink all of your storage offline and have windows clustering say “Yup. That storage is clusterable” or “Nope it wasn’t” while you crush your production environment.
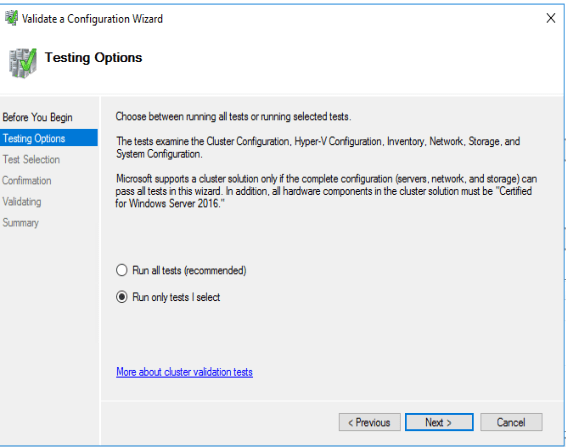
And then.. Just go ahead and untick storage… Your users won’t thank you. You can just quietly know you protected them from yourself (and the Cluster Validation UI) and you lived another day to not have to ponder the state of your resume.
